How to Unlock Watcher's Potential: A Client-First Strategy with Central and Pull Transformation
In this article, we’re going to dive into how we transformed the architecture of the Watcher video surveillance system. We switched things up from a push-based approach for handling configurations and events to a pull-oriented one. This shift didn’t just streamline the code, it also cut down on the overhead associated with managing the video surveillance system, cranked up its performance, and added a layer of stability to the archive, especially in setups involving multiple servers.

The Original Watcher Setup and How It Evolved
Let’s rewind the clock and take a look at how Watcher’s architecture started off. Back in the day, Watcher was made up of two main software components: Watcher itself and the reliable Flussonic Media Server. Watcher, the real brains of the operation, played a vital role in handling all the behind-the-scenes business logic. It held onto critical data about cameras, user and permissions. Watcher also had the important job of sending out settings and configurations to the Flussonic Media Server.Flussonic worked as a streaming server, capturing camera feeds, maintaining video archives, and deciding which segments to keep or delete.
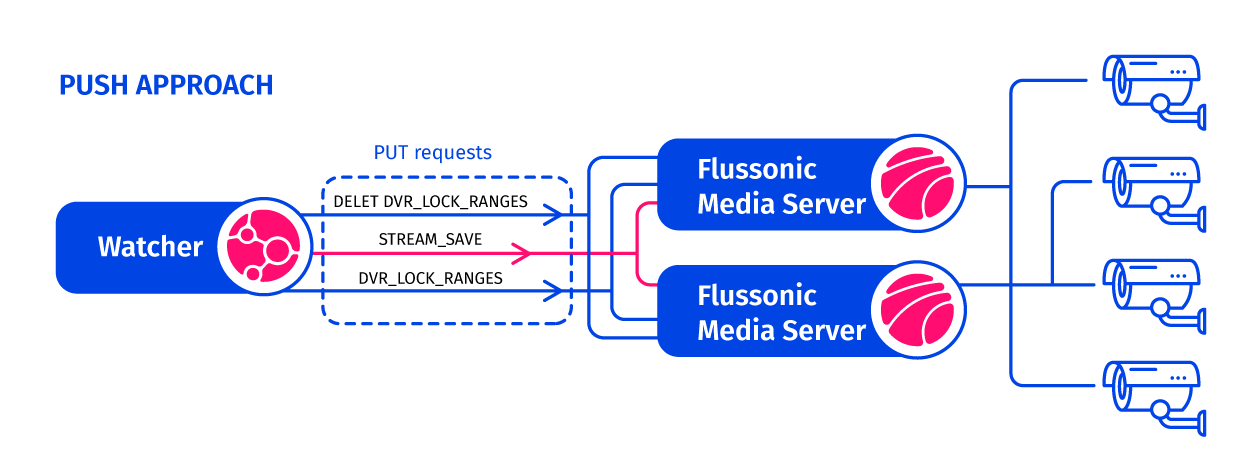
Figure 1. Previous Watcher Architecture without Central
Watcher’s architecture for managing configurations and events operated under a “push” approach. In this setup, a central system takes the lead in triggering the transmission of a configuration to a service-providing system. In our scenario, the Flussonic Media Server played the role of the service, while Watcher functioned as the orchestrator in control.
Watcher took charge of stream management on the media server, handling tasks like creating, deleting, and transferring streams via API-call. A similar approach was taken with the archives. To prevent important events from being erased within a few days, Watcher utilized API commands to create and remove “locks” in the archive. These locks acted as markers, extending the storage duration of specific archive segments beyond the standard lifespan. This function played a vital role by significantly reducing disk usage, often by dozens or even hundreds of times.
Unlock the Secrets of Our Video Surveillance System Transformation!
Subscribe now for exclusive insights.
As the number of cameras and media servers that serve them continues to rise, the need to synchronize states across nodes within a cluster has emerged. This is a common challenge faced in distributed systems. When dispatching a stream or issuing a command to safeguard archive content from deletion, ensuring the successful execution of the command becomes crucial. Moreover, considering that the streaming server itself might experience failures and subsequent restoration from backups, it becomes imperative to guarantee its operation with the most up-to-date configurations.
In the pursuit of addressing these challenges, the architecture can take a complex turn and sacrifice some of its efficiency and elegance. Operations focused on synchronizing states, such as transferring configurations and managing states through commands like “lock this segment in the archive” (DVR_LOCK), began to be executed at a considerable scale by Watcher. This was necessary to prevent the system from becoming too delicate (thus, the introduction of the essential “reset cache” functionality). The result was an impact on the performance of both the Flussonic Media Server and the entire system as a whole.
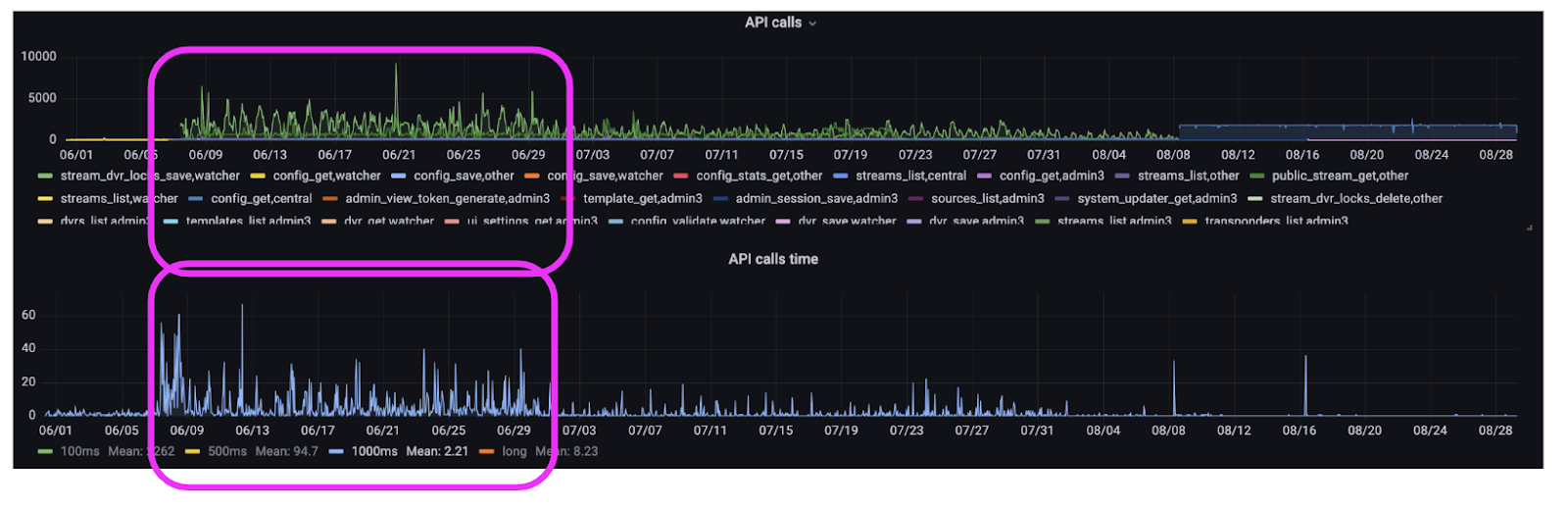
Figure 2. Telemetry Graph: API Calls and API Call execution Times from Watcher Customer. API Calls challenges in June
The upper graph, displaying call frequency, illustrates a distinct “see-saw” pattern from 06/09 to 06/29. During this period, the client found themselves in a state of turmoil due to an unregulated influx of API requests. Requests aimed at locking archive segments (“stream_dvr_lock_save”) were a major contributor to this influx.
This surge in requests had a direct impact on the Flussonic Media Server API’s efficiency, resulting in a less-than-optimal performance. The lower graph further underscores this issue, as it portrays a noticeable rise in the number of API requests taking over one second to process. This sluggishness had a ripple effect across the entire system, leading to a general decline in performance – in simpler terms, everything was slowing down considerably.
Optimization Efforts and Push Approach Challenges
In response to the client’s concerns, we rolled out a new release in July, aiming to fine-tune the volume of API requests to the Flussonic Media Server through Watcher within the push model.

Figure 3. Telemetry Graph: API Calls and API Call execution Times from Watcher Customer. API-Calls optimization within PUSH model
The graph illustrates a noticeable “smoothing” of the trends in July. The number of requests experienced a decrease, as did their processing time. However, this improvement wasn’t quite significant, and the system’s performance slowdown persisted.
Through our investigation, we realized that taking the push approach to configuration management further had its limitations. To be precise, it demands more resources and a greater investment of time for development and fine-tuning. This is because the push approach necessitates the storage of a substantial amount of state data, making it inherently more fragile.
A Fresh Orchestrator and a Paradigm Shift: PUSH vs. PULL in Configuration and Events Management
After recognizing the resource-heavy nature of our attempts to optimize the push model, we made a significant decision to overhaul our strategy for configuration management. This revamp was twofold. First, we extracted the orchestration functions and housed them in a distinct Central system. Second, we transitioned from the conventional “push” methodology to a more innovative “pull” model.
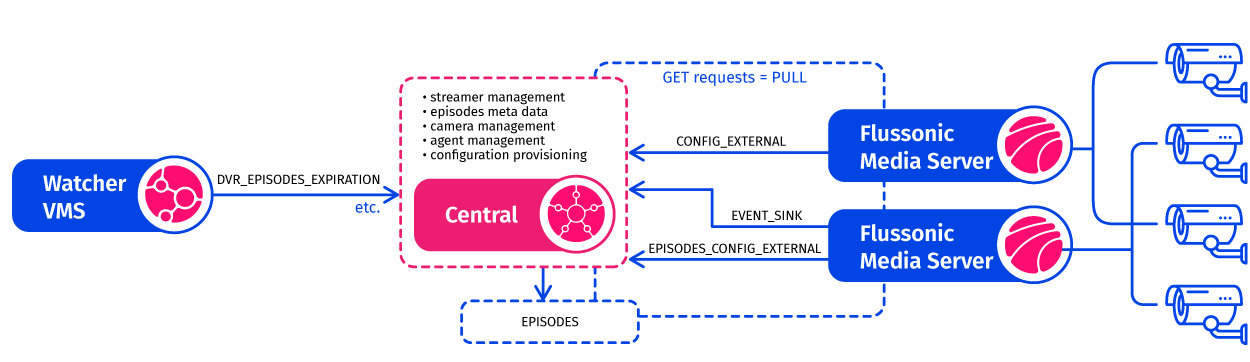
Figure 4. The New Watcher Architecture embracing Central
Let’s dissect the transformation. Central has taken up the responsibility of retaining state knowledge regarding the streamers, or the Flussonic Media Servers. The need for managing this state at the individual media server level has been eliminated. Central serves as the hub where state knowledge and comprehensive configuration details are housed.
In the current scenario, Flussonic Media Server “pulls” updated configurations from Central, which is now the reservoir of state knowledge. This marks a pivotal shift from passively waiting for external “push” updates. This approach establishes a unified point of state information storage. It permits multiple instances of Flussonic Media Servers to fetch this information on a regular basis as required. The key point here is that by shifting from a complicated and convoluted push system to a pull system, we effectively avoid the need to unravel all the complexities and variations in how push updates sometimes fail to be properly received. Instead, we replace them with a consistent process of regularly pulling the desired state.
In the past, updating (pushing) the state on every node within a media server cluster required physically going to each node and migrating the configuration, sharing it among all the nodes. Simultaneously, close monitoring was essential not only for unsuccessful attempts to access the media server but also for servers that experienced sudden rollbacks or manual reconfigurations. Now, rather than needing to visit various nodes to align the state, the state information is consolidated in Central. All nodes retrieve this information from Central as soon as they’re prepared. Consequently, the latest configuration swiftly reaches the streaming server within seconds.
PUSH vs. PULL in archive management
Similarly, we moved from push to pull in managing the archive. First, we switched to the mechanism of storing episodes instead of individual segments. Previously, locking segments in the archive (DVR_LOCK) was controlled by push through Watcher, where each segment in the file system was marked as “locked”. Now Flussonic requests (pulls) information from Central about which episodes should be saved.
Now when the Watcher wants to save or lock an episode, it gets in touch with Central. Central then just logs the details into the database. This action stands out as way less resource-intensive compared to performing an operation involving physical disks.
Central’s database holds all the info about each episode, like when it starts and ends, and might also include things like previews, screenshots, and other bits of info. The actual video and audio content gets stored away on the best-suited node within the cluster. The cluster decides where it’s best placed.
On top of that, this method is much more cost-effective than the old way of “locking” things on three or more Flussonic server disks. Just to clarify, before, we had to hop over to three different media servers, hunt down the right part on one of the disks, and then tinker with the file system to lock it down. But now, instead of going back and forth with Flussonic’s media servers, all we have to do is make a single entry in the Central database. After that, every Flussonic Media Server, even if there’s like a thousand of them, gets the scoop from Central. Central lets them know which parts need to be locked, and the rest can be wiped out.
The client’s transition to the new Watcher configuration with Central and the shift to the pull paradigm
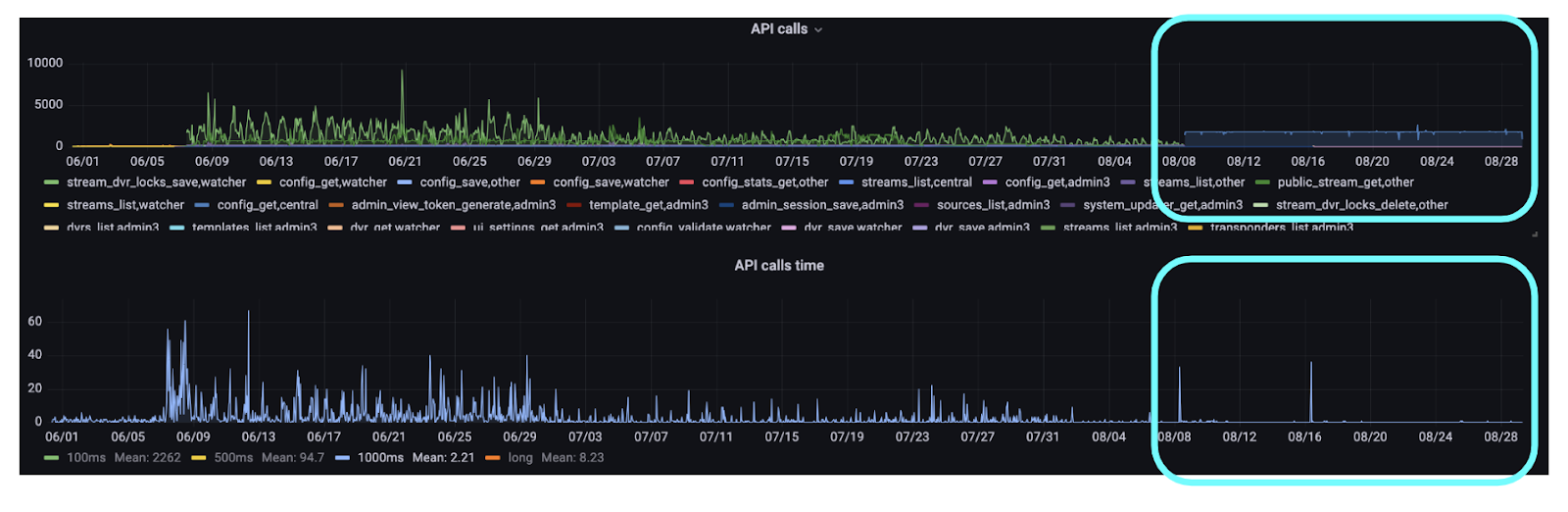
Figure 5. API calls and API calls time graph - big shift after transition to Central in August
In August, our client made a shift to a new Watcher setup, embracing the Central orchestrator alongside a fresh pull-paradigm for overseeing configurations (states), streamers, and archives.
At the top graph, you’ll notice how the count of API requests has taken on an almost “linear” and foreseeable pattern ( the # of requests related to archive locking in particular). Meanwhile, the graph beneath shows how the execution time of these API requests has “smoothed out”.
In sum: with the involvement of Central and the pull-based approach, our client now reaps the benefits of a managed and foreseeable stream of API requests and their processing time. This change has led to reduced consumption of network resources, cut memory and CPU loads in half, and, thanks to the pull-based method, brought about more stability in archive operations!
Conclusions:
-
If you are a Watcher customer and have reservations about making the switch to Central, thinking, “Why fix what isn’t broken?” – let me assure you, hesitation might not be necessary. Real customer examples showcase remarkable enhancements in performance, particularly for extensive, multi camera multi steamer Watcher setups.
-
With the adoption of the pull-approach and the episode-centered mechanism integrated into Central, the cost of organizing archives takes a dive, and the archive itself becomes more resilient against mishaps. This resilience is rooted in the fact that archive metadata is stored within a distinct Central database, while the actual archive content is saved on the most optimal node within the cluster.
-
What’s more, this method opens the door to accommodating a larger count of cameras on a single media server.
-
And to top it all off, here’s the icing on the cake: the pull-oriented approach of Central renders the streamer infrastructure (media servers) stateless. This translates to smoother operation of the video surveillance system in a cloud-based containerized environment, like the one found in Kubernetes.